Extract Records from Excel File¶
In the following getting started tutorial we’ll drive you through the process of extracting data from any Excel file with LogIsland platform.
Both XLSX and old XLS file format are supported.
Note
Be sure to know of to launch a logisland Docker environment by reading the prerequisites section
Note, it is possible to store data in different datastores. In this tutorial, we will see the case of ElasticSearch only.
1.Install required components¶
For this tutorial please make sure to already have installed elasticsearch and excel modules. If not you can just do it through the componentes.sh command line:
bin/components.sh -i com.hurence.logisland:logisland-processor-elasticsearch:1.1.1
bin/components.sh -i com.hurence.logisland:logisland-service-elasticsearch_5_4_0-client:1.1.1
bin/components.sh -i com.hurence.logisland:logisland-processor-excel:1.1.1
2. Logisland job setup¶
The logisland job for this tutorial is already packaged in the tar.gz assembly and you can find it here for ElasticSearch :
docker exec -i -t logisland vim conf/index-excel-spreadsheet.yml
We will start by explaining each part of the config file.
An Engine is needed to handle the stream processing. This conf/extract-excel-data.yml configuration file defines a stream processing job setup.
The first section configures the Spark engine (we will use a KafkaStreamProcessingEngine) to run in local mode with 2 cpu cores and 2G of RAM.
engine:
component: com.hurence.logisland.engine.spark.KafkaStreamProcessingEngine
type: engine
documentation: Index records of an excel file with LogIsland
configuration:
spark.app.name: IndexExcelDemo
spark.master: local[4]
spark.driver.memory: 1G
spark.driver.cores: 1
spark.executor.memory: 2G
spark.executor.instances: 4
spark.executor.cores: 2
spark.yarn.queue: default
spark.yarn.maxAppAttempts: 4
spark.yarn.am.attemptFailuresValidityInterval: 1h
spark.yarn.max.executor.failures: 20
spark.yarn.executor.failuresValidityInterval: 1h
spark.task.maxFailures: 8
spark.serializer: org.apache.spark.serializer.KryoSerializer
spark.streaming.batchDuration: 1000
spark.streaming.backpressure.enabled: false
spark.streaming.unpersist: false
spark.streaming.blockInterval: 500
spark.streaming.kafka.maxRatePerPartition: 3000
spark.streaming.timeout: -1
spark.streaming.unpersist: false
spark.streaming.kafka.maxRetries: 3
spark.streaming.ui.retainedBatches: 200
spark.streaming.receiver.writeAheadLog.enable: false
spark.ui.port: 4050
The controllerServiceConfigurations part is here to define all services that be shared by processors within the whole job, here an Elasticsearch service that will be used later in the BulkAddElasticsearch processor.
- controllerService: elasticsearch_service
component: com.hurence.logisland.service.elasticsearch.Elasticsearch_5_4_0_ClientService
type: service
documentation: elasticsearch service
configuration:
hosts: sandbox:9300
cluster.name: es-logisland
batch.size: 5000
Inside this engine you will run a Kafka stream of processing, so we setup input/output topics and Kafka/Zookeeper hosts.
Here the stream will read all the logs sent in logisland_raw topic and push the processing output into logisland_events topic.
We can define some serializers to marshall all records from and to a topic. We assume that the stream will be serializing the input file as a byte array in a single record. Reason why we will use a ByteArraySerialiser in the configuration below.
# main processing stream
- stream: parsing_stream
component: com.hurence.logisland.stream.spark.KafkaRecordStreamParallelProcessing
type: stream
documentation: a processor that converts raw excel file content into structured log records
configuration:
kafka.input.topics: logisland_raw
kafka.output.topics: logisland_events
kafka.error.topics: logisland_errors
kafka.input.topics.serializer: com.hurence.logisland.serializer.BytesArraySerializer
kafka.output.topics.serializer: com.hurence.logisland.serializer.KryoSerializer
kafka.error.topics.serializer: com.hurence.logisland.serializer.JsonSerializer
kafka.metadata.broker.list: sandbox:9092
kafka.zookeeper.quorum: sandbox:2181
kafka.topic.autoCreate: true
kafka.topic.default.partitions: 4
kafka.topic.default.replicationFactor: 1
Within this stream, an ExcelExtract processor takes a byte array excel file content and computes a list of Record.
# parse excel cells into records
- processor: excel_parser
component: com.hurence.logisland.processor.excel.ExcelExtract
type: parser
documentation: a parser that produce events from an excel file
configuration:
record.type: excel_record
skip.rows: 1
field.names: segment,country,product,discount_band,units_sold,manufacturing,sale_price,gross_sales,discounts,sales,cogs,profit,record_time,month_number,month_name,year
This stream will process log entries as soon as they will be queued into logisland_raw Kafka topics, each log will
be parsed as an event which will be pushed back to Kafka in the logisland_events topic.
Note
Please note that we are mapping the excel column Date to be the timestamp of the produced record (record_time field) in order to use this as time reference in elasticsearch/kibana (see below).
The second processor will handle Records produced by the ExcelExtract to index them into elasticsearch
# add to elasticsearch
- processor: es_publisher
component: com.hurence.logisland.processor.elasticsearch.BulkAddElasticsearch
type: processor
documentation: a processor that trace the processed events
configuration:
elasticsearch.client.service: elasticsearch_service
default.index: logisland
default.type: event
timebased.index: yesterday
es.index.field: search_index
es.type.field: record_type
3. Launch the script¶
For this tutorial we will handle an excel file. We will process it with an ExcelExtract that will produce a bunch of Records and we’ll send them to Elastiscearch Connect a shell to your logisland container to launch the following streaming jobs.
For ElasticSearch :
docker exec -i -t logisland bin/logisland.sh --conf conf/index-excel-spreadsheet.yml
4. Inject an excel file into the system¶
Now we’re going to send a file to logisland_raw Kafka topic.
For testing purposes, we will use kafkacat, a generic command line non-JVM Apache Kafka producer and consumer which can be easily installed.
Note
Sending raw files through kafka is not recommended for production use since kafka is designed for high throughput and not big message size.
The configuration above is suited to work with the example file Financial Sample.xlsx.
Let’s send this file in a single message to LogIsland with kafkacat to logisland_raw Kafka topic
kafkacat -P -t logisland_raw -v -b sandbox:9092 ./Financial\ Sample.xlsx
5. Inspect the logs¶
Kibana¶
With ElasticSearch, you can use Kibana.
Open up your browser and go to http://sandbox:5601/ and you should be able to explore your excel records.
Configure a new index pattern with logisland.* as the pattern name and @timestamp as the time value field.
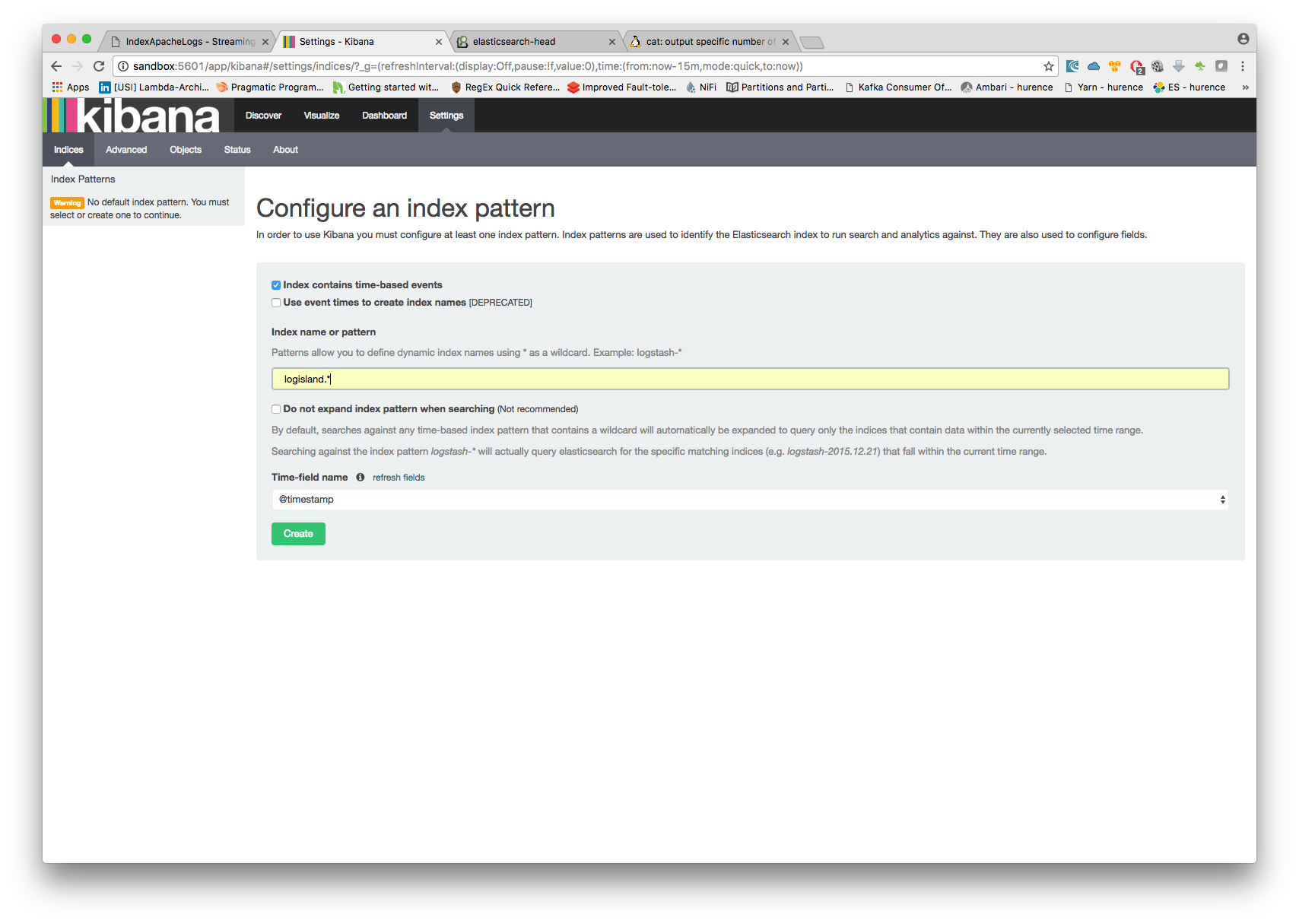
Then if you go to Explore panel for the latest 5 years time window. You are now able to play with the indexed data.

Thanks logisland! :-)