Apache logs indexing with mongo¶
In the following getting started tutorial we’ll drive you through the process of Apache log mining with LogIsland platform. The final data will be stored in mongo
This tutorial is very similar to :
Note
Please note that you should not launch silmutaneously several docker-compose because we are exposing local port in them. So running several at the same time would be conflicting. So be sure to have killed all your currently running containers.
1.Install required components¶
You either use docker-compose with available docker-compose-index-apache-logs-mongo.yml file in the tar.gz assembly in the conf folder.
In this case you can skip this section
Or you can launch the job in your cluster, but in this case you will have to make changes to job conf file so it works in your environment.
In this case please make sure to already have installed mongo modules (depending on which base you will use).
If not you can just do it through the components.sh command line:
bin/components.sh -i com.hurence.logisland:logisland-service-mongodb-client:1.1.2
Note
In the following sections we will use docker-compose to run the job. (please install it before pursuing if you are not using your own cluster)
2. Logisland job setup¶
The logisland job that we will use is ./conf/index-apache-logs-mongo.yml The logisland docker-compose file that we will use is ./conf/docker-compose-index-apache-logs-mongo.yml
We will start by explaining each part of the config file.
An Engine is needed to handle the stream processing. This conf/index-apache-logs-mongo.yml configuration file defines a stream processing job setup.
The first section configures the Spark engine (we will use a KafkaStreamProcessingEngine) to run in local mode with 2 cpu cores and 2G of RAM.
engine:
component: com.hurence.logisland.engine.spark.KafkaStreamProcessingEngine
type: engine
documentation: Index some apache logs with logisland
configuration:
spark.app.name: IndexApacheLogsDemo
spark.master: local[2]
spark.driver.memory: 1G
spark.driver.cores: 1
spark.executor.memory: 2G
spark.executor.instances: 4
spark.executor.cores: 2
spark.yarn.queue: default
spark.yarn.maxAppAttempts: 4
spark.yarn.am.attemptFailuresValidityInterval: 1h
spark.yarn.max.executor.failures: 20
spark.yarn.executor.failuresValidityInterval: 1h
spark.task.maxFailures: 8
spark.serializer: org.apache.spark.serializer.KryoSerializer
spark.streaming.batchDuration: 1000
spark.streaming.backpressure.enabled: false
spark.streaming.unpersist: false
spark.streaming.blockInterval: 500
spark.streaming.kafka.maxRatePerPartition: 3000
spark.streaming.timeout: -1
spark.streaming.kafka.maxRetries: 3
spark.streaming.ui.retainedBatches: 200
spark.streaming.receiver.writeAheadLog.enable: false
spark.ui.port: 4050
The controllerServiceConfigurations part is here to define all services that be shared by processors within the whole job,
here an mongo service that will be used later in the TODO processor.
- controllerService: datastore_service
component: com.hurence.logisland.service.mongodb.MongoDBControllerService
type: service
documentation: "Mongo 3.8.0 service"
configuration:
mongo.uri: ${MONGO_URI}
mongo.db.name: logisland
mongo.collection.name: apache
# possible values ACKNOWLEDGED, UNACKNOWLEDGED, FSYNCED, JOURNALED, REPLICA_ACKNOWLEDGED, MAJORITY
mongo.write.concern: ACKNOWLEDGED
flush.interval: 2000
batch.size: 100
Note
As you can see it uses environment variable so make sure to set them. (if you use the docker-compose file of this tutorial it is already done for you)
Inside this engine you will run a Kafka stream of processing, so we setup input/output topics and Kafka/Zookeeper hosts.
Here the stream will read all the logs sent in logisland_raw topic and push the processing output into logisland_events topic.
Note
We want to specify an Avro output schema to validate our ouput records (and force their types accordingly). It’s really for other streams to rely on a schema when processing records from a topic.
We can define some serializers to marshall all records from and to a topic.
- stream: parsing_stream
component: com.hurence.logisland.stream.spark.KafkaRecordStreamParallelProcessing
type: stream
documentation: a processor that converts raw apache logs into structured log records
configuration:
kafka.input.topics: logisland_raw
kafka.output.topics: logisland_events
kafka.error.topics: logisland_errors
kafka.input.topics.serializer: none
kafka.output.topics.serializer: com.hurence.logisland.serializer.KryoSerializer
kafka.error.topics.serializer: com.hurence.logisland.serializer.JsonSerializer
kafka.metadata.broker.list: ${KAFKA_BROKERS}
kafka.zookeeper.quorum: ${ZK_QUORUM}
kafka.topic.autoCreate: true
kafka.topic.default.partitions: 4
kafka.topic.default.replicationFactor: 1
Note
As you can see it uses environment variable so make sure to set them. (if you use the docker-compose file of this tutorial it is already done for you)
Within this stream a SplitText processor takes a log line as a String and computes a Record as a sequence of fields.
# parse apache logs into logisland records
- processor: apache_parser
component: com.hurence.logisland.processor.SplitText
type: parser
documentation: a parser that produce events from an apache log REGEX
configuration:
record.type: apache_log
value.regex: (\S+)\s+(\S+)\s+(\S+)\s+\[([\w:\/]+\s[+\-]\d{4})\]\s+"(\S+)\s+(\S+)\s*(\S*)"\s+(\S+)\s+(\S+)
value.fields: src_ip,identd,user,record_time,http_method,http_query,http_version,http_status,bytes_out
This stream will process log entries as soon as they will be queued into logisland_raw Kafka topics, each log will
be parsed as an event which will be pushed back to Kafka in the logisland_events topic.
The second processor will handle Records produced by the SplitText to index them into solr
# all the parsed records are added to mongo by bulk - processor: mongo_publisher
component: com.hurence.logisland.processor.datastore.BulkPut type: processor documentation: “indexes processed events in Mongo” configuration:
datastore.client.service: datastore_service
3. Launch the job¶
1. Run docker-compose¶
For this tutorial we will handle some apache logs with a splitText parser and send them to Elastiscearch. Launch your docker container with this command (we suppose you are in the root of the tar gz assembly) :
sudo docker-compose -f ./conf/docker-compose-index-apache-logs-es.yml up -d
Make sure all container are running and that there is no error.
sudo docker-compose ps
Those containers should be visible and running
``` CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0d9e02b22c38 docker.elastic.co/kibana/kibana:5.4.0 “/bin/sh -c /usr/loc…” 13 seconds ago Up 8 seconds 0.0.0.0:5601->5601/tcp conf_kibana_1 ab15f4b5198c docker.elastic.co/elasticsearch/elasticsearch:5.4.0 “/bin/bash bin/es-do…” 13 seconds ago Up 7 seconds 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp conf_elasticsearch_1 a697e45d2d1a hurence/logisland:1.1.2 “tail -f bin/logisla…” 13 seconds ago Up 9 seconds 0.0.0.0:4050->4050/tcp, 0.0.0.0:8082->8082/tcp, 0.0.0.0:9999->9999/tcp conf_logisland_1 db80cdf23b45 hurence/zookeeper “/bin/sh -c ‘/usr/sb…” 13 seconds ago Up 10 seconds 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 7072/tcp conf_zookeeper_1 7aa7a87dd16b hurence/kafka:0.10.2.2-scala-2.11 “start-kafka.sh” 13 seconds ago Up 5 seconds 0.0.0.0:9092->9092/tcp conf_kafka_1
sudo docker logs conf_kibana_1
sudo docker logs conf_elasticsearch_1
sudo docker logs conf_logisland_1
sudo docker logs conf_zookeeper_1
sudo docker logs conf_kafka_1
Should not return errors or any suspicious messages
2. Initializing mongo db¶
Note
You have to create the db logisland with the collection apache.
# open the mongo shell inside mongo container
sudo docker exec -ti conf_mongo_1 mongo
> use logisland
switched to db logisland
> db.apache.insert({src_ip:"19.123.12.67", identd:"-", user:"-", bytes_out:12344, http_method:"POST", http_version:"2.0", http_query:"/logisland/is/so?great=true",http_status:"404" })
WriteResult({ "nInserted" : 1 })
> db.apache.find()
{ “_id” : ObjectId(“5b4f3c4a5561b53b7e862b57”), “src_ip” : “19.123.12.67”, “identd” : “-”, “user” : “-”, “bytes_out” : 12344, “http_method” : “POST”, “http_version” : “2.0”, “http_query” : “/logisland/is/so?great=true”, “http_status” : “404” }
3. Run logisland job¶
you can now run the job inside the logisland container
sudo docker exec -ti conf_logisland_1 ./bin/logisland.sh --conf ./conf/index-apache-logs-mongo.yml
The last logs should be something like :
2019-03-19 16:08:47 INFO StreamProcessingRunner:95 - awaitTermination for engine 1 2019-03-19 16:08:47 WARN SparkContext:66 - Using an existing SparkContext; some configuration may not take effect.
4. Inject some Apache logs into the system¶
Now we’re going to send some logs to logisland_raw Kafka topic.
If you don’t have your own httpd logs available, you can use some freely available log files from NASA-HTTP web site access:
- Jul 01 to Jul 31, ASCII format, 20.7 MB gzip compressed
- Aug 04 to Aug 31, ASCII format, 21.8 MB gzip compressed
- Let’s send the first 500 lines of NASA http access over July 1995 to LogIsland with kafka scripts
- (available in our logisland container) to
logisland_rawKafka topic.
In another terminal run those commands
sudo docker exec -ti conf_logisland_1 bash
cd /tmp
wget ftp://ita.ee.lbl.gov/traces/NASA_access_log_Jul95.gz
gunzip NASA_access_log_Jul95.gz
head -n 500 NASA_access_log_Jul95 | ${KAFKA_HOME}/bin/kafka-console-producer.sh --broker-list kafka:9092 --topic logisland_raw
5. Monitor your spark jobs and Kafka topics¶
Now go to http://localhost:4050/streaming/ to see how fast Spark can process your data
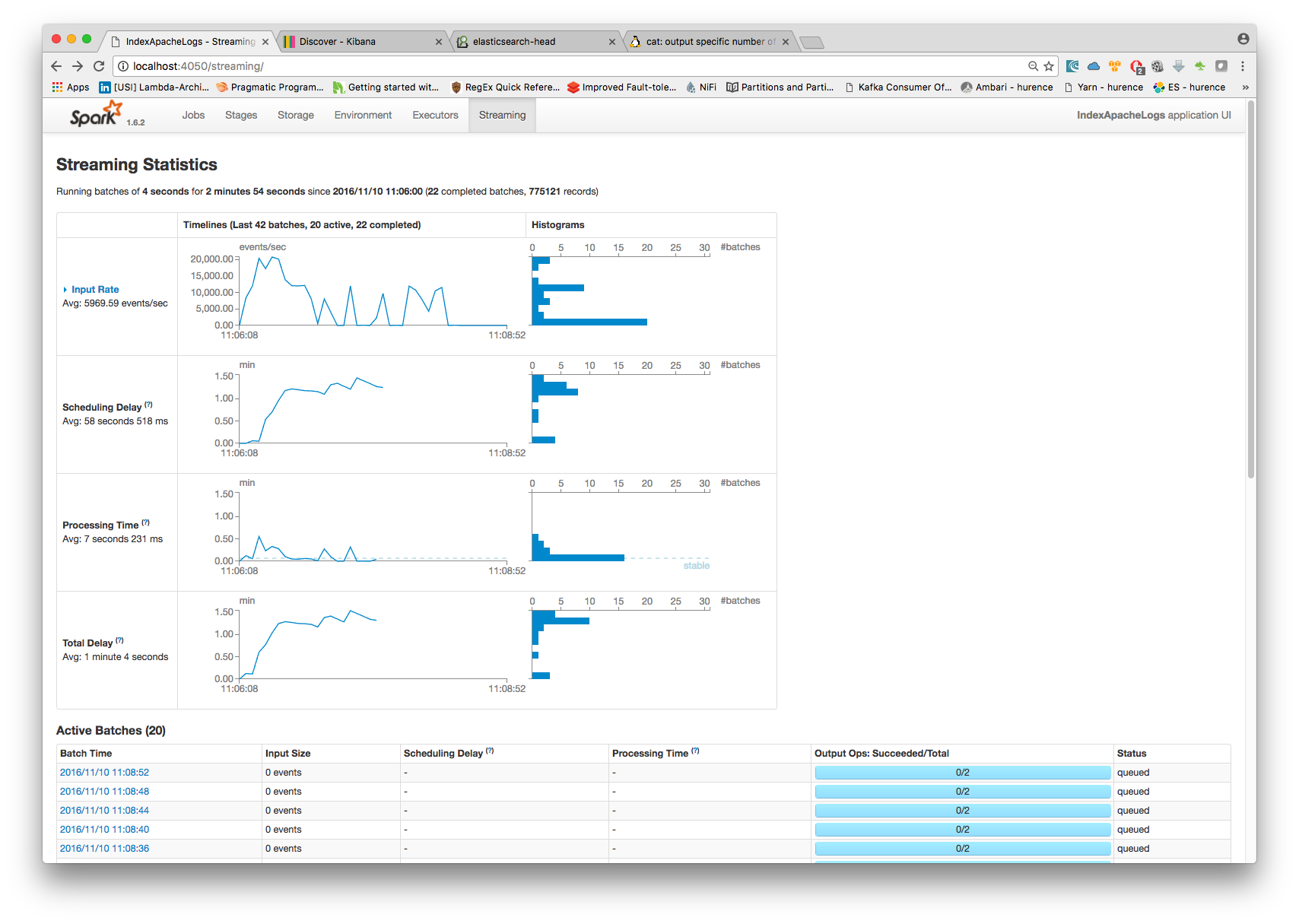
6. Inspect the logs¶
With mongo you can directly use the shell:
> db.apache.find()
{ “_id” : “507adf3e-3162-4ff0-843a-253e01a6df69”, “src_ip” : “129.94.144.152”, “record_id” : “507adf3e-3162-4ff0-843a-253e01a6df69”, “http_method” : “GET”, “record_value” : “129.94.144.152 - - [01/Jul/1995:00:00:17 -0400] “GET /images/ksclogo-medium.gif HTTP/1.0” 304 0”, “http_query” : “/images/ksclogo-medium.gif”, “bytes_out” : “0”, “identd” : “-”, “http_version” : “HTTP/1.0”, “http_status” : “304”, “record_time” : NumberLong(“804571.1.4.1”), “user” : “-”, “record_type” : “apache_log” } { “_id” : “c44a9d09-52b9-4ada-8126-39c70c90fdd3”, “src_ip” : “ppp-mia-30.shadow.net”, “record_id” : “c44a9d09-52b9-4ada-8126-39c70c90fdd3”, “http_method” : “GET”, “record_value” : “ppp-mia-30.shadow.net - - [01/Jul/1995:00:00:27 -0400] “GET / HTTP/1.0” 200 7074”, “http_query” : “/”, “bytes_out” : “7074”, “identd” : “-”, “http_version” : “HTTP/1.0”, “http_status” : “200”, “record_time” : NumberLong(“804571.4.100”), “user” : “-”, “record_type” : “apache_log” } …
3. Stop the job¶
You can Ctr+c the console where you launched logisland job. Then to kill all containers used run :
sudo docker-compose -f ./conf/docker-compose-index-apache-logs-es.yml down
Make sure all container have disappeared.
sudo docker ps